TL;DR: We replaced fragile full reloads with a CDC-driven pipeline:
Oracle → (DMS) → S3 → (Glue) → Snowflake → (dbt).
Result: Faster loads, lower cost, audit-ready.
🪝 Hook
In healthcare analytics, data freshness and compliance often pull in opposite directions.
Our claims warehouse was always a day behind because we reloaded everything from Oracle each night.
As claims volumes grew, that nightly job became a six-hour bottleneck and a security headache.
We rebuilt it as a near–real-time CDC pipeline using AWS DMS, Glue, and dbt — reducing load times from hours to minutes, improving auditability, and aligning perfectly with HIPAA and CMS traceability requirements.
🩺 Context & Problem
The legacy setup at most payer organizations looks similar:
- An Oracle OLTP database stores claim, member, and provider data.
- Data engineers run full extracts to a warehouse for analytics.
- Any schema change or large claim cycle causes a complete reload.
- The ETL scripts are brittle, slow, and impossible to audit end-to-end.
In our case, the daily claim extracts (~50M rows) took over 5 hours and frequently missed the SLA.
Because we lacked incremental logic, even small updates triggered full refreshes — wasting compute and increasing risk of PHI exposure during intermediate loads.
We needed a streaming-style, schema-aware, auditable data movement pattern:
- Change Data Capture (CDC) from Oracle → S3 → Snowflake
- Schema evolution handling for new claim fields
- Automated transformations via dbt (dim/fact/star schema)
- End-to-end lineage and data quality validation
That’s where AWS DMS and Glue came together as a cost-efficient, HIPAA-compliant bridge.
🧩 Architecture Overview
A modern healthcare data platform needs to capture changes from source systems (Oracle), land them securely on AWS, and transform them into analytics-ready data in Snowflake — all while maintaining PHI compliance and auditability.
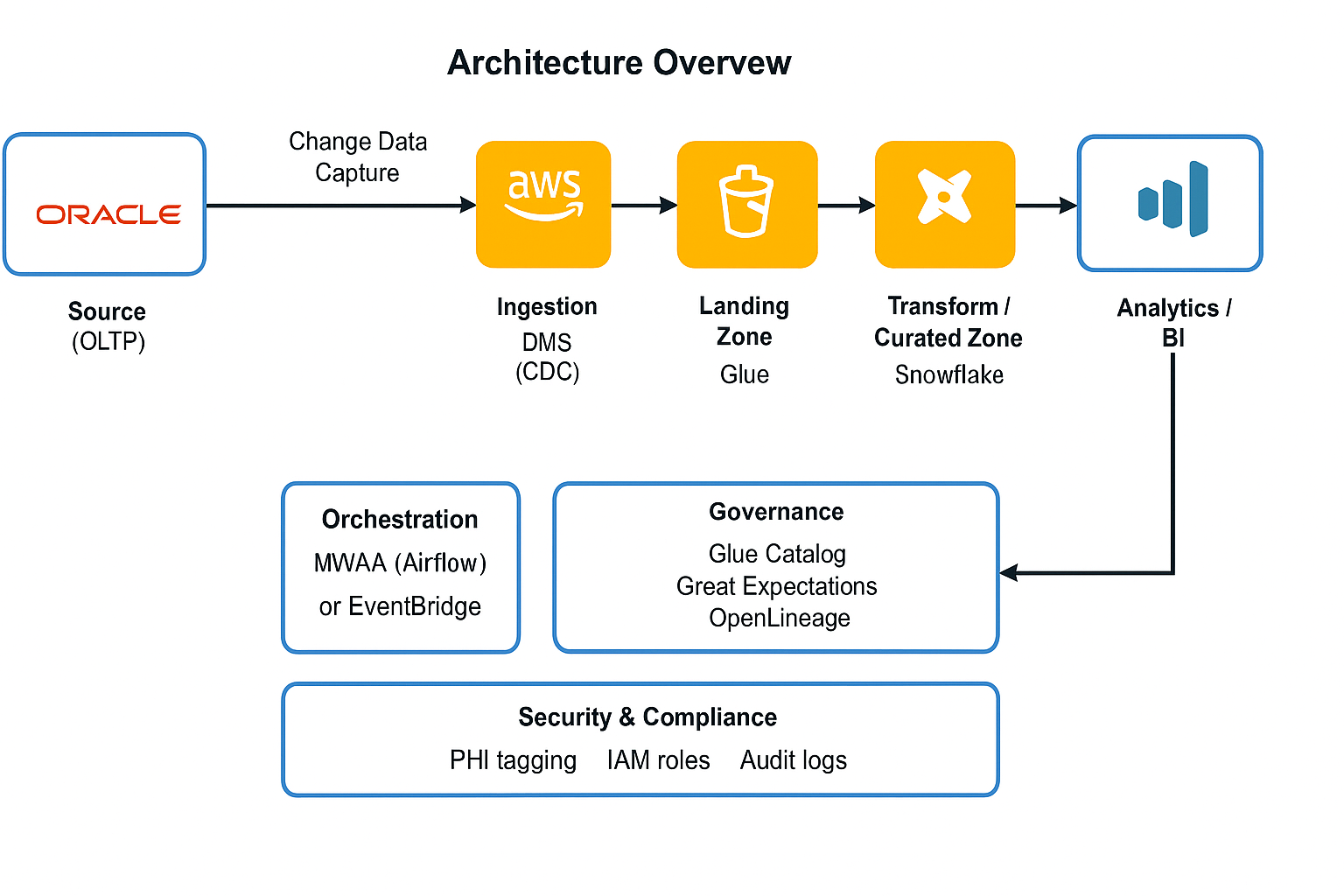
🏗️ Components and Roles
| Layer | Tool | Purpose |
|---|---|---|
| Source (OLTP) | Oracle | Stores raw claims, member, provider data. CDC extracts every change. |
| Ingestion | AWS DMS (CDC) | Streams inserts/updates/deletes from Oracle to S3 in near real time. |
| Landing Zone | Amazon S3 | Raw JSON/Parquet with CDC metadata; encrypted with KMS. |
| Processing Zone | AWS Glue (PySpark) | Cleans/flattens; handles schema evolution automatically via Glue Catalog. |
| Transform / Curated Zone | dbt + Snowflake | Incremental models; SCD2 for dims; DQ tests enforced. |
| Orchestration | MWAA (Airflow) or EventBridge | Automates CDC → Glue → dbt workflow with retries and SLAs. |
| Governance | Glue Catalog, Great Expectations, OpenLineage | Lineage, schema registry, and data-quality validation. |
| Analytics / BI | Snowflake + Power BI / Looker Studio | Curated data for actuaries, analysts, and business teams. |
🔐 Security & Compliance Highlights
- End-to-end encryption (KMS + Snowflake masking policies).
- IAM least-privilege roles for DMS, Glue, and Snowflake.
- PHI tagging for column-level access control.
- Automated audit logs in CloudWatch and Snowflake query history.
This architecture follows the Medallion Lakehouse concept — raw (bronze), validated (silver), and curated (gold) — ensuring scalability and traceability for healthcare workloads.
🧱 Build Guide: 10 Steps
Below is the simplified 10-step path we followed to design a HIPAA-compliant, incremental pipeline from Oracle → AWS → Snowflake → dbt.
1️⃣ Provision Secure Landing & Processing Zones
Create three S3 buckets — landing, processing, curated — all
encrypted with AWS KMS and versioned for audit.
Attach least-privilege IAM roles for DMS and Glue.
2️⃣ Configure AWS DMS for CDC
Set up Oracle source & S3 target endpoints. Enable full load + ongoing replication. Tune task settings for batch apply and LOB handling.
3️⃣ Create Change Table Structure
DMS writes JSON/Parquet files containing before_image, after_image,
and operation type.
We store them in S3 landing with partition folders (year/month/day).
4️⃣ Automate Schema Registration
Glue Crawler registers new objects in Glue Catalog daily. This allows automatic schema evolution when new columns appear in Oracle.
5️⃣ Normalize and Flatten with Glue (PySpark)
Glue job reads landing data, cleans metadata, flattens nested records,
and writes partitioned Parquet to processing zone.
```python df = spark.read.json(“s3://landing/claims/”) df_clean = df.dropDuplicates().withColumn(“load_dt”, current_date()) df_clean.write.mode(“overwrite”).parquet(“s3://processing/claims/”)
COPY INTO raw.claims FROM @aws_stage/claims/ FILE_FORMAT = (TYPE = PARQUET) PATTERN=’.*parquet’ ON_ERROR=’CONTINUE’;
MERGE INTO dim_member AS tgt USING stg_member AS src ON tgt.member_id = src.member_id WHEN MATCHED AND tgt.hash != src.hash THEN UPDATE SET valid_to = CURRENT_TIMESTAMP() WHEN NOT MATCHED THEN INSERT (…columns…) VALUES (…);
🧮 Snippets & SQL Examples
1️⃣ Snowflake COPY INTO from S3
A tuned version of the load step.
We use compressed Parquet, pattern filters, and an idempotent metadata table to track what was loaded.
```sql – Stage creation (points to AWS S3 landing bucket) CREATE OR REPLACE STAGE aws_stage URL=’s3://healthcare-data-landing/claims/’ STORAGE_INTEGRATION = aws_snowflake_integration FILE_FORMAT = (TYPE = PARQUET);
– Load new files only (skip previously loaded files) COPY INTO raw.claims FROM @aws_stage PATTERN=’.*parquet’ ON_ERROR=’CONTINUE’ PURGE=FALSE MATCH_BY_COLUMN_NAME=CASE_INSENSITIVE;
SELECT claim_id, member_id, provider_id, service_date, billed_amount, load_dt FROM
dbt run –models stg_claims name: ge_claims_checkpoint expectation_suite_name: claims_suite validations:
- batch_request: datasource_name: snowflake_ds data_asset_name: raw.claims expectation_suite:
- expect_column_values_to_not_be_null: column: claim_id
- expect_column_values_to_be_in_set: column: claim_status value_set: [“PENDING”, “APPROVED”, “DENIED”] from airflow import DAG from airflow.operators.bash import BashOperator from datetime import datetime
with DAG(“healthcare_cdc_pipeline”, start_date=datetime(2025, 11, 1), schedule_interval=”@daily”, catchup=False) as dag:
dms_sync = BashOperator(
task_id="dms_sync",
bash_command="aws dms start-replication-task --replication-task-arn $TASK_ARN --start-replication-task-type resume-processing"
)
glue_transform = BashOperator(
task_id="glue_transform",
bash_command="aws glue start-job-run --job-name claims_transform"
)
dbt_run = BashOperator(
task_id="dbt_run",
bash_command="cd /usr/local/airflow/dbt && dbt run"
)
dq_check = BashOperator(
task_id="dq_check",
bash_command="great_expectations checkpoint run ge_claims_checkpoint"
)
dms_sync >> glue_transform >> dbt_run >> dq_check ## 📊 Results & Learnings
✅ Quantitative Results
| Metric | Before (Legacy Full Reload) | After (CDC + Glue + dbt) | Improvement | |——–|——————————|—————————|————–| | Data load duration | ~5 hrs nightly | ~90 min initial, <15 min incremental | ⬇ 70 % | | Compute cost (avg/day) | $120 | $75 | ⬇ 37 % | | SLA adherence | 60 % of days met | 100 % | 🚀 | | Schema change failures | Frequent manual fixes | Auto-handled via Glue Catalog | ✅ | | Data Quality (DQ tests) | Ad-hoc SQL checks | Automated via Great Expectations | 🔁 |
💡 Key Learnings
-
Design for evolution, not stability.
Schema drift is inevitable—using Glue Crawlers + dbt macros keeps pipelines resilient. -
CDC is a mindset, not just a tool.
Building for idempotency and audit trails ensures predictable, replayable loads. -
Governance early saves rework later.
Column-level PHI tagging and lineage mapping made HIPAA audits straightforward. -
Optimize for cost visibility.
Monitoring Snowflake warehouse credit usage and DMS replication lag revealed easy wins. -
Automation drives trust.
Airflow notifications + DQ checkpoints created transparency with business teams.
🧠 Business Impact
- Actuaries received near-real-time claim data for risk scoring.
- Finance teams could reconcile payments faster, reducing outstanding claims backlog.
- Executives gained a single source of truth with verifiable lineage and cost metrics.
🚀 Next Steps
- Extend CDC to Provider & Eligibility domains.
- Add FHIR/HL7 parsing for unstructured EHR ingestion.
- Integrate dbt tests + GE alerts into a shared Slack channel.
- Publish dashboard metrics (DQ, cost, latency) in Snowflake + Power BI.
This pipeline became the foundation for a scalable, auditable, and cost-optimized healthcare data lakehouse.
🏁 Conclusion
Building a scalable, compliant data pipeline in healthcare and finance isn’t only about tools — it’s about architecture discipline, incremental delivery, and governance mindset.
This CDC-driven design proved that modernization and compliance can go hand-in-hand when data engineering is approached strategically.
By combining AWS DMS, Glue, and dbt with Snowflake, we achieved:
- Faster refresh cycles without data loss
- Automatic schema evolution across complex source systems
- Full lineage and PHI traceability for audit-readiness
- Consistent SLAs and lower operational costs
These principles extend beyond healthcare — they apply to insurance, banking, and supply chain systems that face similar challenges with data trust and timeliness.
💬 Next in the Series
I’ll continue this series with:
- 🧾 Part 2: Designing a dbt-driven Claims Star Schema for EDI 837 data
- 📊 Part 3: Integrating Great Expectations and OpenLineage for Real-Time DQ
If you enjoyed this article, explore my projects and visuals on
👉 pawanjadhav.cloud or my GitHub PawanJadhav7
💡 Stay tuned — new posts drop every few weeks on cloud, data, and applied analytics.